Polyphonic sound event detection
Short version
For my MSc thesis, I wrote software that:
- Classifies bird species from song.
- Tags the moments in time where birds are singing with a frame-wise F-score of 0.94.
- Distinguishes bird song phrases in an unsupervised manner.
In addition I created a dataset with 3200+ annotated songs, with 500+ sound event annotations for each of 5 bird species.
[code] [paper] [video]
Long versions
While looking for a subject for my MSc thesis, I was reading about the use of neural networks for spectrogram analysis. There were several annual competitions in classifying bird species from spectrograms, as is the fashion for many problems in machine learning. The winning entries in these competitions exclusively used CNNs [1]. A few things bothered me about these entries:
- Standard CNNs necessarily interpret both axes of a spectrogram as spatially related, which is questionable. These axes encode two distinct features, frequency and time.
- There was an absence of multiclass classification, while real-life recordings often contain multiple species singing at once.
- There was little mention of ways to extend these models for practical applications, such as biomonitoring and population counting.
Thus, I set out to find a method or network architecture that could address these issues. I was led to a paper by Adavanne et al. that presents a network called sed-crnn [2-3]. The central idea is to cut up the spectrogram along the time axis. The resulting vectors represent the frequencies present at single time steps. Here, a time step is a discretization of time, whose length depends on the parametrization of the spectrogram’s STFT. By splitting time, we can now process time and frequency separately. Frequencies are processed by convolutional layers, while the time interdependencies are processed by a recurrent neural network. Adding sigmoid activations for each class, rather than using a softmax for a dominant class, gives us a network capable of polyphonic sound event detection.
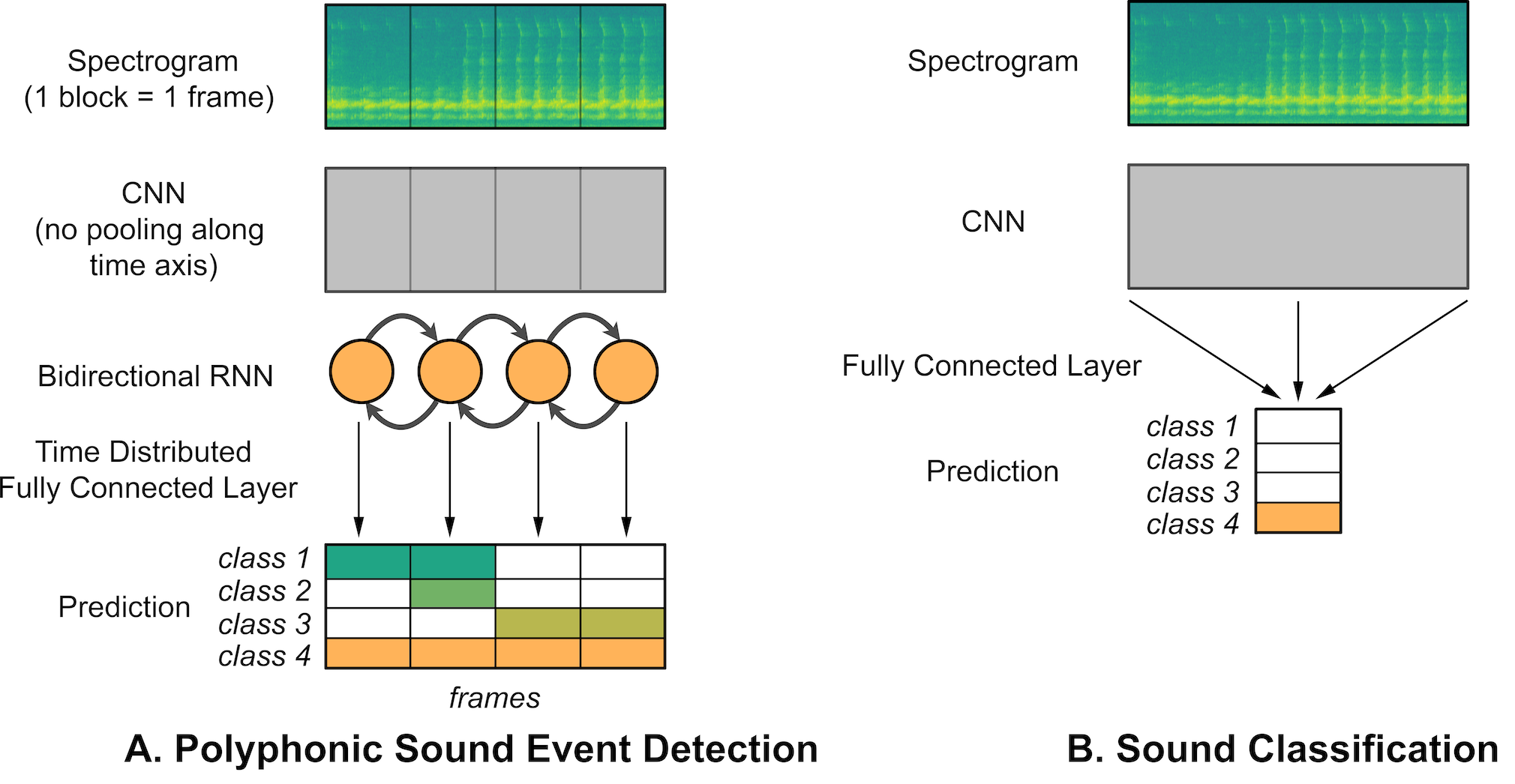
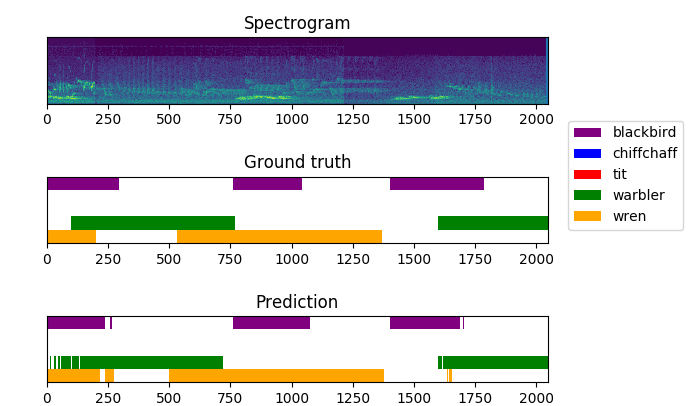
I took the model’s source code and rewrote it from the ground up to improve the modularity, conciseness, and simplicity. This model worked exceptionally well for the regularities present in the dataset I annotated (F-score of 0.94 vs 0.59 reported in the original sed-crnn paper) . So well in fact, that I was extremely sceptical it was real. After careful analysis and finding no mistakes such as train/test overlap, I included a section of possible explanation in the paper. These include repetitive song structures, data quality, and parameter choices.
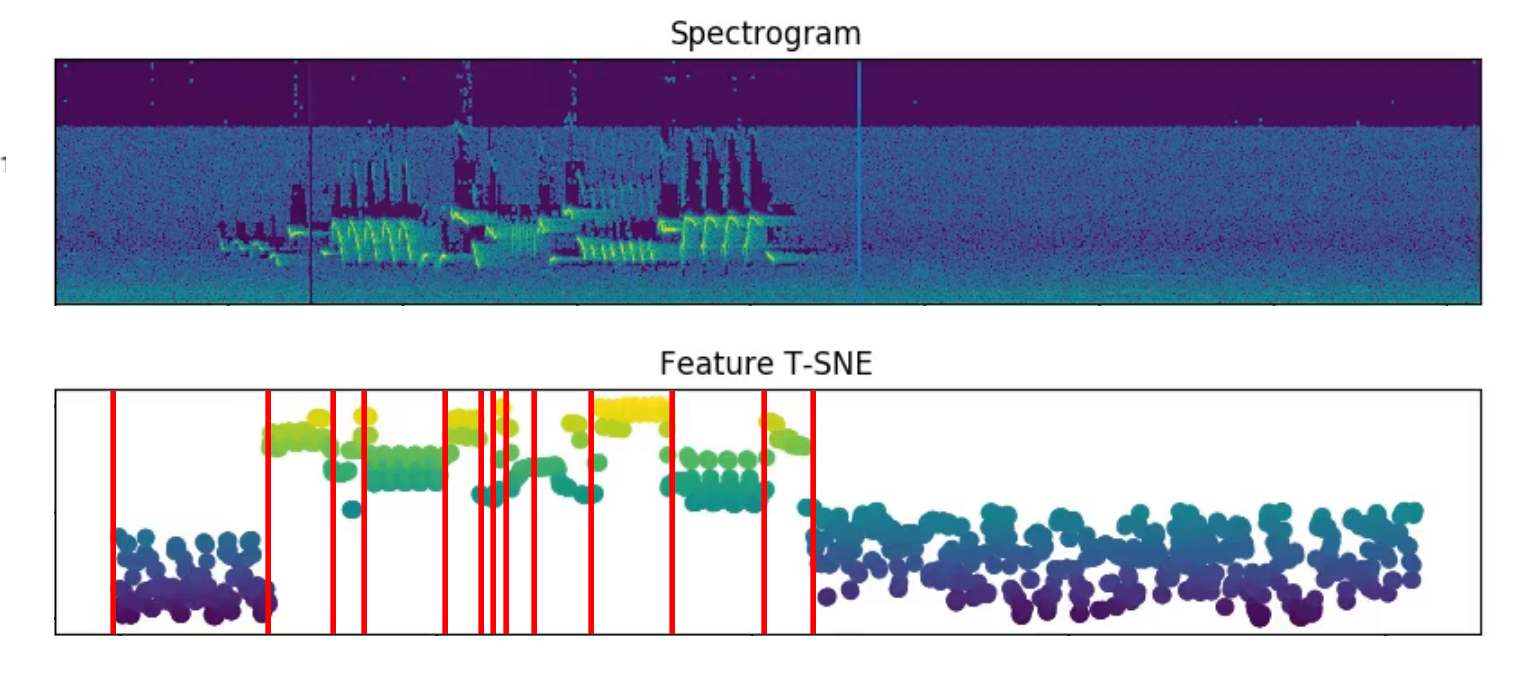
Last but not least, the trained network has a surprising capacity to segment song phrases. During development, I would plot the 1D T-SNE of the CNN features as a sanity check. As it turns out, these features covary with song phrases, and applying K-means clustering to the CNN features is enough to signify phrase edges.
[1] Kahl et al. - Recognizing Birds from Sound - The 2018 BirdCLEF Baseline System
[2] Adavanne et al. - Sound event detection using spatial features and convolutional recurrent neural network
[3] Sed-crnn Github repository