Eulerian Video Magnification
Short version
I wrote an open-source implementation and reproduced the results of a work named Eulerian Video Magnification for Revealing Subtle Changes in the World.
The code in the repository can:
- Magnify subtle motion changes, such as a guitar string vibrating or a human chest expanding during inhalation
- Magnify subtle color changes, such as changes in facial redness due to human pulse.
- Use any of 3 different signal filters (Butterworth, ideal, and simplified IIR)
- Reproduce any of the paper’s experiments with a single function call.
- Magnify videos of any shape. Unlike the original implementation, where frame width and height must be a power of 2.
Long version
Whilst reading up on computer vision methods to exaggerate motion for a project, I came across this paper. The work garnered quite some media attention in November 2014 when one of the authors presented it in a TED talk. The popularity may have been due to how the applications speak to the imagination, such as converting subtle motions to audio waves and revealing structural looseness in machinery.
The technique is fairly straightforward. For motion magnification, each frame is decomposed into its Laplacian pyramid. In short, this captures the frame’s information at different scales and allows one to target large- and small-scale changes independently. Here, large-scale could be the movement of a limb, and small-scale the movement of a hair.
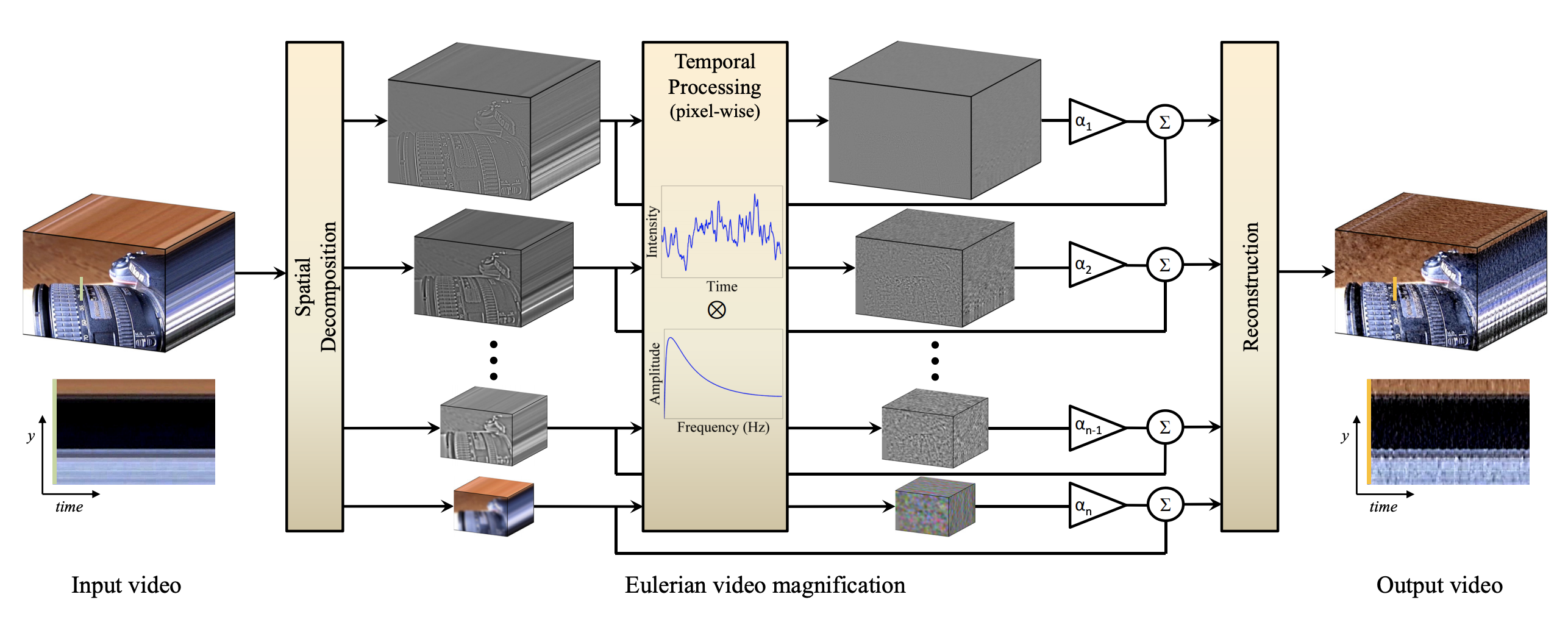 Figure from the paper
Figure from the paper
By using multiple frames, one can consider not just information but changes at different scales. By applying a digital signal filter along all frames, one can select only the changes that occur at a certain frequency. These filtered movements are then amplified and added to the original video. Thus, the motion is magnified. Color magnification follows a similar principle. A Gaussian pyramid is constructed - color changes are filtered and amplified at a certain scale and frequency - the amplified signal is added to the original video.
Final remarks
Like many classical computer vision techniques, there is a lot of parameter tweaking involved. One can achieve impressive results by choosing parameters wisely e.g., by setting filter cutoffs near the frequency of the change of interest (average human pulse) or doing parameter search. Nevertheless, this technique requires some parameter tweaking for every sample, making it impractical for a production environment. I was pleased to see that the authors have since shifted their focus to the more flexible Learning-based Video Motion Magnification. I would like to reproduce that work in the future as well.